Abstract
- Pre-trained models with a differentiable access mechanism to explicit non-parametric memory have so far been only investigated for extractive downstream tasks.
- pre-trained models
- non-parametric memory
- differentiable access mechanism
- In soft differentiable access mechanism, we don’t discard any chunks.
- In Hard retrieval (standard RAG), the retriever picks the top-k passages
- We introduce RAG models where the parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever.
- pre-trained models → seq2seq model
- non-parametric memory → a dense vector index of Wikipedia
- differentiable access mechanism → a pre-trained neural retriever
1. Prompt (question) arrives.
2. Seq2seq encoder turns it into query vector q.
3. Retriever compares q to all memory keys k_i (Wikipedia passage vectors).
4. Compute similarity scores s_i = q ⋅ k_i.
5. Apply softmax → attention weights α_i.
6. Read vector r = Σ α_i v_i (weighted mixture of passage info).
7. Feed r (plus q) into seq2seq decoder → generate answer token by token.
8. Gradients flow through α_i → retriever learns to attend to more relevant chunks.
text chunk → retriever encoder → key/value → FAISS index → query embedding → top-k retrieval → generator
- We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, and another which can use different passages per token.
- same retrieved passages → RAG-Sequence
- different passages per token → RAG-Token
It’s often used for knowledge-intensive tasks, not free-form story generation.
Discussion
We conducted an thorough investigation of the learned retrieval component, validating its effectiveness, and we illustrated how the retrieval index can be hot-swapped to update the model without requiring any retraining.
This is one of RAG’s biggest advantages over standard language models:
- You can update its knowledge base without retraining its parameters.
The retriever learns the mapping → parametric
The index just holds the results → non-parametric
| Retriever model | A neural network that encodes queries and documents into vectors. | Parametric — it has learnable weights (parameters) |
|---|---|---|
| Retrieval index (memory) | The database of all document embeddings (keys + values) | Non-parametric — stored outside the model’s paras |
Index = structure that accelerates similarity search using ANN methods (cluster-and-search) (ANN -> Approximate nearest neighbor).
Key = pre-computed document embedding;
Value = original text (encoded later when used).
Hard retrieval = pick top-k texts → concatenate → generator sees text.
Soft retrieval = mix all embeddings by attention → generator sees one read vector.
Generator (e.g., BART or T5): a Transformer-based seq2seq model.
1. Introduction
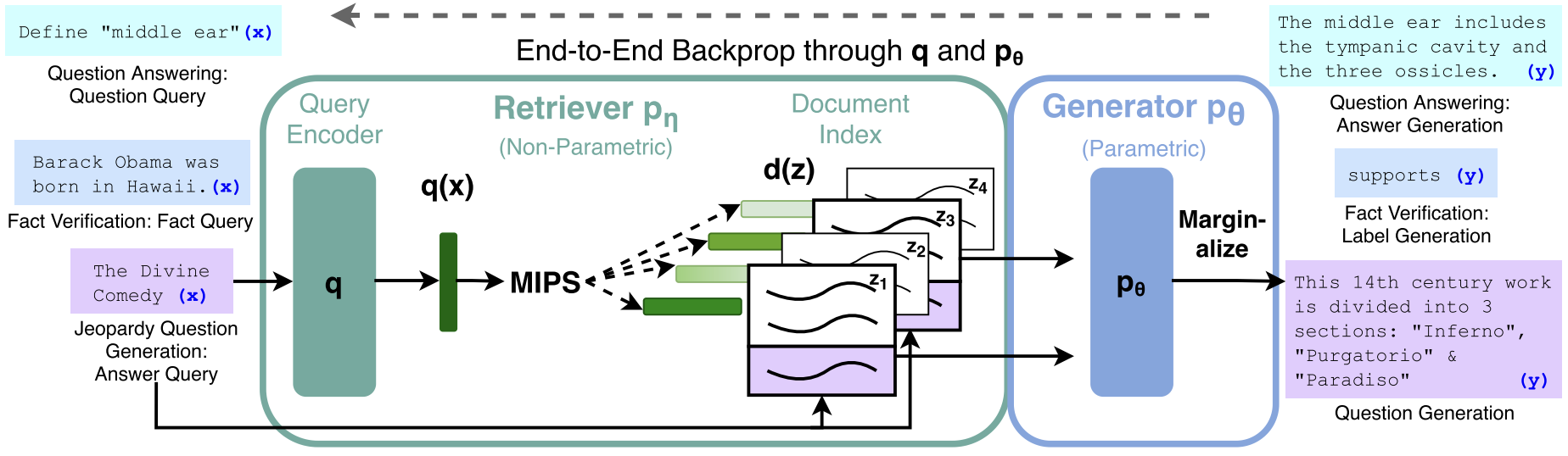
RAG can be fine-tuned on any seq2seq task, whereby both the generator and retriever are jointly learned.
We can make an anology:
- RAG's retriever is like encoder, because it summarizes what info the model should pay attention to before generation.
- RAG's generator is like decoder, because it generate the sequence token-by-token.
Steps
- The retriever (Dense Passage Retriever, henceforth DPR) provides latent documents conditioned on the input,
- The seq2seq model (BART) then conditions on these latent documents together with the input to generate the output.
2. Methods
Our models leverage 2 components:
- a retriever $p_η(z|x)$
- a generator $p_θ(y_i|x, z, y_{1:i−1})$
x = the query (e.g., a question or a sentence you want to search with)
z = a text passage (a possible relevant document)
η = the parameters of the model/retriever
**p(z∣x) = the prob that passage z is relevant to the query x**
---
y1:i-1 = the previous i-1 tokens
z = the retrieved passage
x = the original input
**pθ(yi|x, z, y1:i−1) = the prob that generating token yi, give three inputs.**
We propose 2 models (based on the average of the latent documents in different ways to produce a distribution over generated text) :
- RAG-Token → can predict each target token based on a different doc/chunk.
- RAG-Sequence → the model uses the same doc/chunk to predict each target token.
2.1 Models
RAG-Sequence Model: The RAG-Sequence model uses the same retrieved doc/chunk to generate the complete seq.
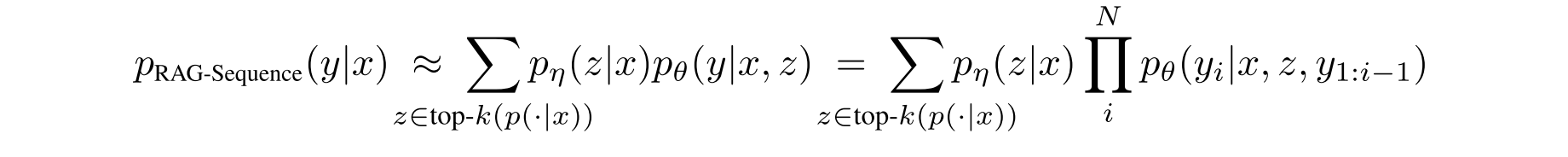
RAG-Token Model: we can draw a different latent document for each target token and marginalize accordingly.
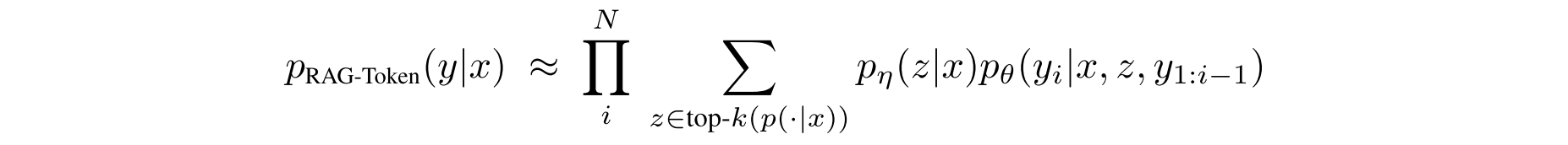
2.2 Retriever: DPR
We use a pre-trained bi-encoder from DPR to initialize our retriever and to build the document index. We refer to the document index as the non-parametric memory.
- DPR (Dense Passage Retriever): a bi-encoder architecture:
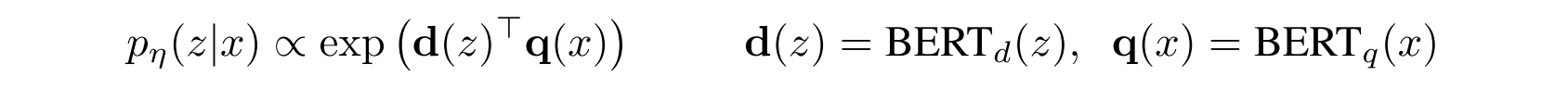
d(z) = a dense representation of a document produced by a BERT document encoder.
q(x) = a query representation produced by a query encoder, also based on BERT.
- MIPS (Maximum Inner Product Search) → The operation of finding top-k documents by inner product between query and every docs.
2.3 Generator: BART
We use BART-large, a pre-trained seq2seq transformer with 400M parameters. We simply concatenate the input x and the retrieved content z.
BART combines the strengths of BERT and GPT:
- BERT: bidirectional understanding (encoder)
- GPT: left-to-right generation (decoder)
2.4 Training
We jointly train the retriever and generator components without any direct supervision on what document should be retrieved.
Updating the document encoder **BERTd** during training is costly as it requires
the document index to be periodically updated as **REALM** does during pre-training.
We do not find this step necessary for strong performance, and
keep the document encoder (and index) fixed,
only fine-tuning the query encoder **BERTq** and the **BART generator**.
BERTd = document encoder
BERTq = query encoder
REALM = Retrieval-Enhanced Adaptive Language Model
update the doc encoder required re-encoding all documents every few steps —
which made it extremely slow and hard to scale.
2.5 Decoding
At test time, RAG-Sequence and RAG-Token require different ways to approximate $arg max_y p(y|x)$.
- RAG-Token Model: standard beam search
- RAG-Sequence Model: Thorough Decoding or Fast Decoding
An autoregressive model = predicts the next token based on all previous tokens.
- Thorough Decoding = Generate and score candidate answers for every retrieved document, then combine their probabilities - most accurate but slow.
- Fast Decoding = Only score candidates that were actually generated during beam search, skipping others — much faster but approximate.
RAG-Token
- 在生成过程中,模型会参考每个 chunk 下的条件概率分布:$p_\theta(y_i \mid x, z, y_{1:i-1})$ 来预测下一个 token 的可能性。
- 然后根据检索器给出的每个 chunk 的权重 $p_\eta(z|x)$,对这些分布进行加权融合,得到一个综合的下一词概率分布:$p’(y_i \mid x, y_{1:i-1}) = \sum_z p_\eta(z|x),p_\theta(y_i \mid x, z, y_{1:i-1})$
- 模型从这个融合分布中选出概率最高的 token,再将其加入到已生成的序列中。
- 重复该步骤,直到生成完整句子。
RAG-Sequence (Thorough Decoding)
- 先在每个 chunk 下独立运行 beam search,得到概率最高的候选句子;
- 然后将这些候选句分别在其他 chunk 上重新计算生成概率 $p_\theta(y|x,z)$(使用 teacher forcing 强制生成),
- 最后根据每个 chunk 的检索权重 $p_\eta(z|x)$ 对句子概率进行加权求和:$p(y|x) = \sum_z p_\eta(z|x),p_\theta(y|x,z)$
- 最终选出整体概率最高的句子作为输出。
RAG-Sequence (Fast Decoding)
- 先在每个 chunk 下生成概率最高的候选句子,
- 但只在生成过该句子的 chunk上计算概率,
- 未生成该句子的 chunk 直接忽略(认为概率≈0),
- 再进行同样的加权求和。
| Comparison Item | RAG-Token | RAG-Sequence (Thorough) | RAG-Sequence (Fast) |
|---|---|---|---|
| Fusion Timing | Dynamically fuses predictions from all chunks at each token | Uses a fixed chunk for the whole sentence, then re-evaluates globally | Uses a fixed chunk for the whole sentence, then re-evaluates locally |
| Fusion Granularity | Token-level | Sentence-level | Sentence-level |
| Decoding Method | Single beam search | Multiple beam searches + full re-evaluation | Multiple beam searches + partial re-evaluation |
| Cross-chunk Generation | ✅ Allowed | ❌ Not allowed | ❌ Not allowed |
| Accuracy | Medium | Highest | High |
| Speed | Fast | Slow | Faster |
| Typical Usage | Common for online inference | Mainly theoretical analysis / small-scale experiments | Practical trade-off in real applications |
| Probability Computation | Sum across chunks at each token | Sum across chunks after full sentence generation | Sum across chunks after full sentence generation |
| Core Idea | Fuse multiple chunk predictions at every step | Generate each sentence independently, then globally combine | Generate each sentence independently, then combine locally |
| Key Characteristics | Each word leverages all chunks — very fast but may produce inconsistent sentences | Theoretically most accurate but computationally slow | Approximate yet efficient — widely used in practice |
3. Experiments
For all experiments:
- Non-parametric knowledge source: the December 2018 dump
- Each Wikipedia article is split into disjoint 100-word chunks, to make a total of 21M docs.
- Build a single MIPS index using FAISS with a Hierarchical Navigable Small World approximation for fast retrieval.
During training:
- We retrieve the top k documents for each query.
- We consider k ∈ {5, 10} for training and set k for test time using dev data.
3.1 Open-domain Question Answering
Compare with:
- The extractive QA paradigm – extracts short answer spans directly from retrieved documents, relying mainly on non-parametric knowledge.
- The Closed-Book QA approaches – generate answers without retrieval, depending only on parametric knowledge stored in the model.
Consider four popular open-domain QA datasets:
- Natural Questions (NQ)
- TriviaQA (TQA)
- WebQuestions (WQ)
- CuratedTrec (CT)
(CT and WQ are small; models are initialized from the NQ-trained RAG model.)
Evaluate:
- Performance is measured using Exact Match (EM) –
- a metric that checks whether the generated answer exactly matches the reference answer.
3.2 Abstractive Question Answering
Evaluate:
- The MSMARCO NLG v2.1 task, which tests RAG’s ability to generate free-form, natural language answers in a knowledge-intensive setting.
Setup:
- Each example includes a question, ten gold retrieved passages, and a full-sentence human-written answer.
- RAG ignores the supplied passages and treats MSMARCO as an open-domain QA task (retrieving from Wikipedia instead).
Note:
- Some questions cannot be answered correctly without the gold passages (e.g., “What is the weather in Volcano, CA?”).
- In such cases, RAG relies on its parametric knowledge to generate reasonable responses.
3.3 Jeopardy Question Generation
Task:
- Given an answer entity, generate a factual Jeopardy-style question (reverse QA).
Dataset:
- SearchQA, with 100K train / 14K dev / 27K test examples.
Compare:
- RAG vs BART (baseline model).
Evaluate:
- Q-BLEU-1 metric (favors entity matching and factual accuracy).
- Human evaluation on two criteria:
- Factuality — whether the question is factually correct.
- Specificity — whether the question is closely related to the given answer.
3.4 Fact Verification
Task:
- Given a claim, classify whether it is supported, refuted, or not enough info using evidence from Wikipedia.
Dataset:
- FEVER benchmark.
Method:
- Map each class label to a single output token, treating the task as sequence classification.
- RAG trains without supervision on retrieved evidence, learning retrieval and reasoning jointly.
Evaluate:
- Report label accuracy for both:
- 3-way classification: supports / refutes / not enough info
- 2-way classification: supports / refutes
Purpose:
- Test RAG’s capability for reasoning-based classification, not just text generation.
4. Results
- Open-domain Question Answering
- Abstractive Question Answering
- Jeopardy Question Generation
- Fact Verification
Table 1 & 2
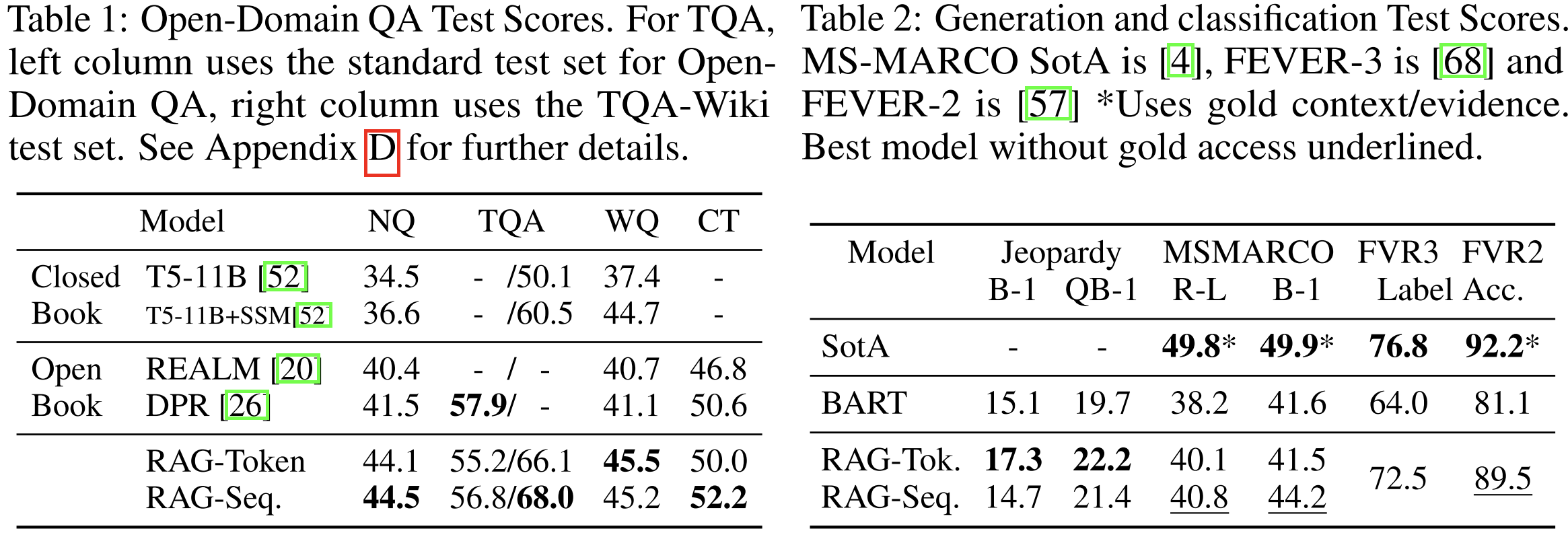
Table 3

Table 4 & 5
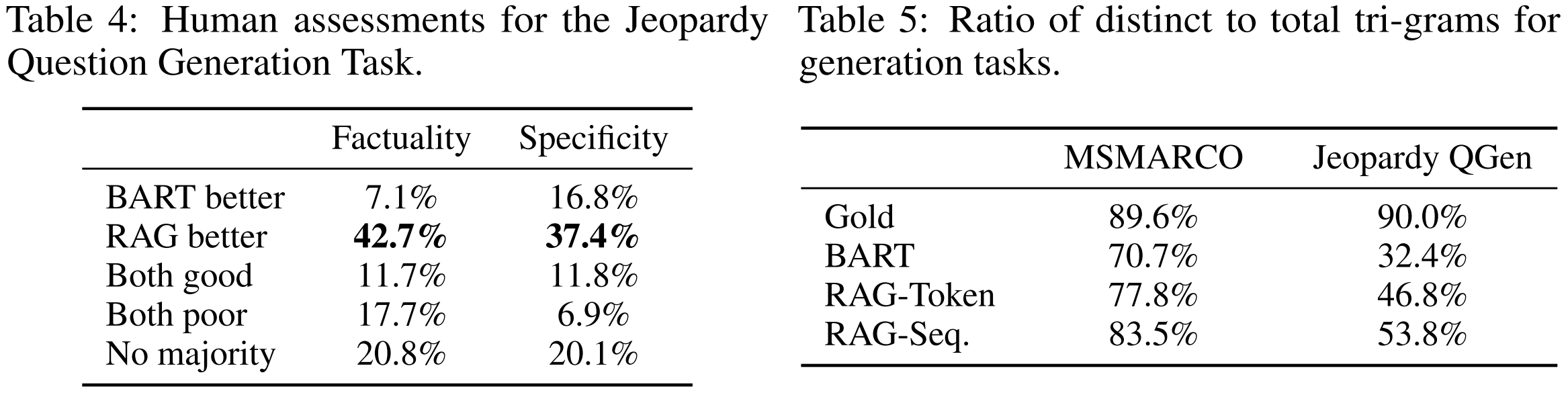
- Factuality → Is the question factually correct?
- Specificity → Does the question precisely match its given answer (not too generic)?
Table 6
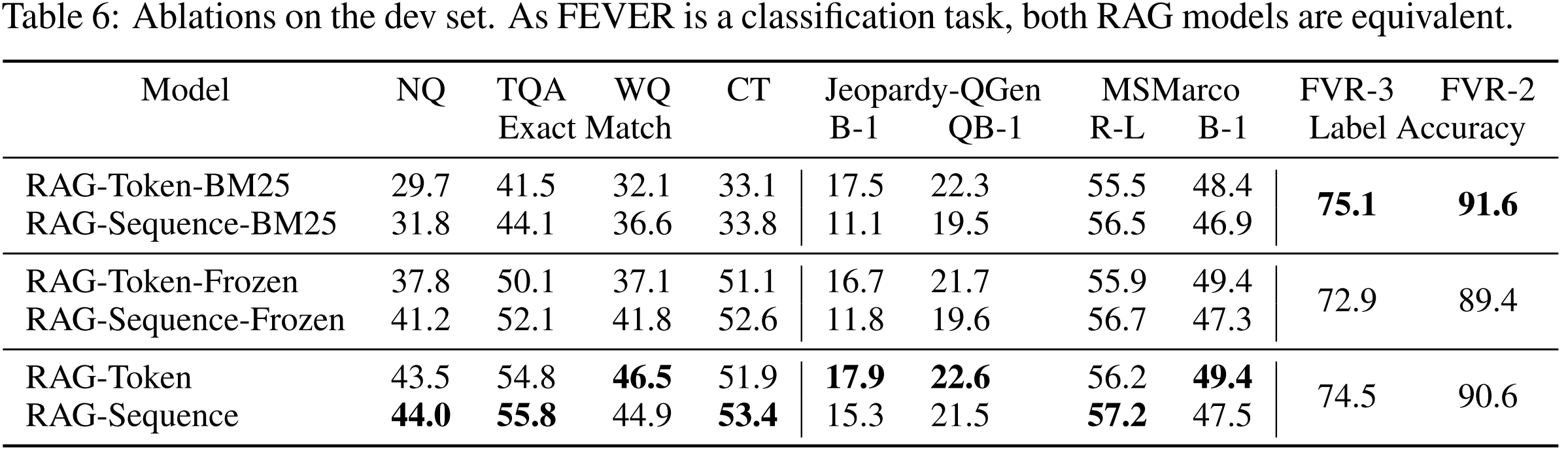
“Ablation” means removing or changing a part of the model to test how much it matters.
Figure 2

The heatmap (right) shows which retrieved document (y-axis) the model relies on when generating each token (x-axis) of a sentence.
The heatmap shows a dark blue cell at (Doc 2, “Sun”), which means Doc 2 — the one containing “The Sun Also Rises” — is strongly influencing this token. (The model correctly “looks up” the document that mentions that book.)
After that, the dark blue (posterior weight) flattens — it spreads out across documents. That means: once the model has started generating “The Sun…”, it can finish “Also Rises” without continuing to depend on that document.