1. Abstract# Background:
summarization → Traditional RAG works well for specific questions (“When was Company X founded?”), but it struggles with broad , global ones (“What are the main ideas in all these documents?”).scalability → (Such questions need summarization of the whole dataset , not just retrieving a few passages — that’s called query-focused summarization (QFS).) Prior QFS methods, meanwhile, do not scale to the quantities of text indexed by typical RAG systems.we need to combine scalability and summarization: combines knowledge graph generation and query-focused summarization GraphRAG ,
a graph-based approach to question answering over private text corpora that scales with both the generality of user questions and the quantity of source text.
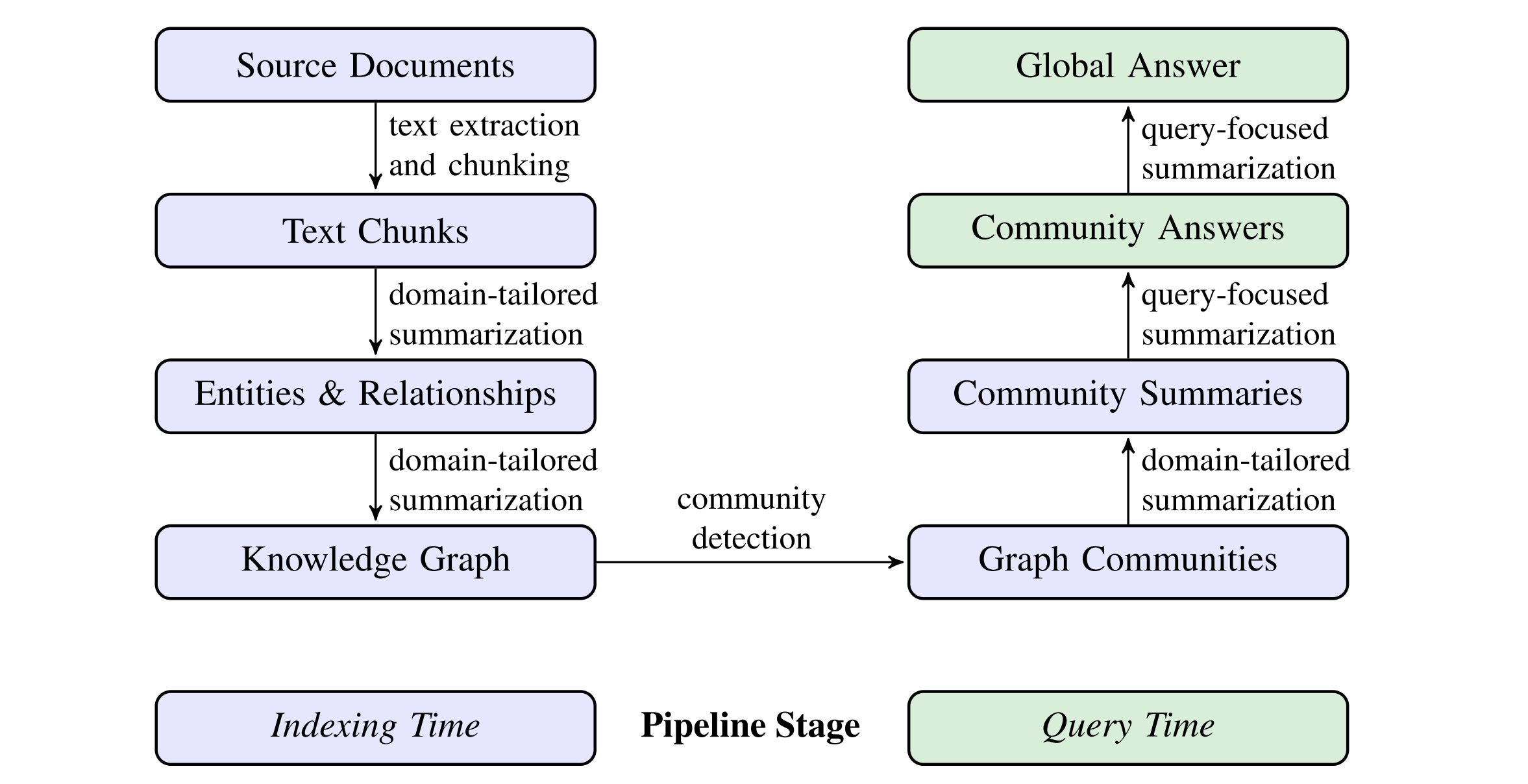
Build a graph index in two stages:
derive an entity knowledge graph from the source documents.a knowledge graph (nodes = entities, edges = relationships) pre-generate community summaries for all groups of closely related entities. Given a question, each community summary is used to generate a partial response, before
all partial responses are again summarized in a final response to the user.
1. Introduction# GraphRAG,
uses an LLM to construct a knowledge grapha knowledge graph, nodes correspond to key entities in the corpus and edges represent relationships between those entities. it partitions the graph into a hierarchy of communities of closely related entities, before using an LLM to generate community-level summaries. GraphRAG answers queries through map-reduce processing of community summaries.In the map step → the summaries are used to provide partial answers to the query independently and in parallel, In the reduce step → the partial answers are combined and used to generate a final global answer. GraphRAG contrasts with vector RAG (text embeddings) in its ability to answer queries that require global sensemaking over the entire data corpus.
2. Background# Adaptive Benchmarking → the process of dynamically generating evaluation benchmarks tailored to specific domains or use cases.
Generating test questions based on the current knowledge base. Measuring how well the model adapts when the corpus changes. Evaluating both retrieval and generation quality together. 3. Methods# The high-level data flow of the GraphRAG approach and pipeline:
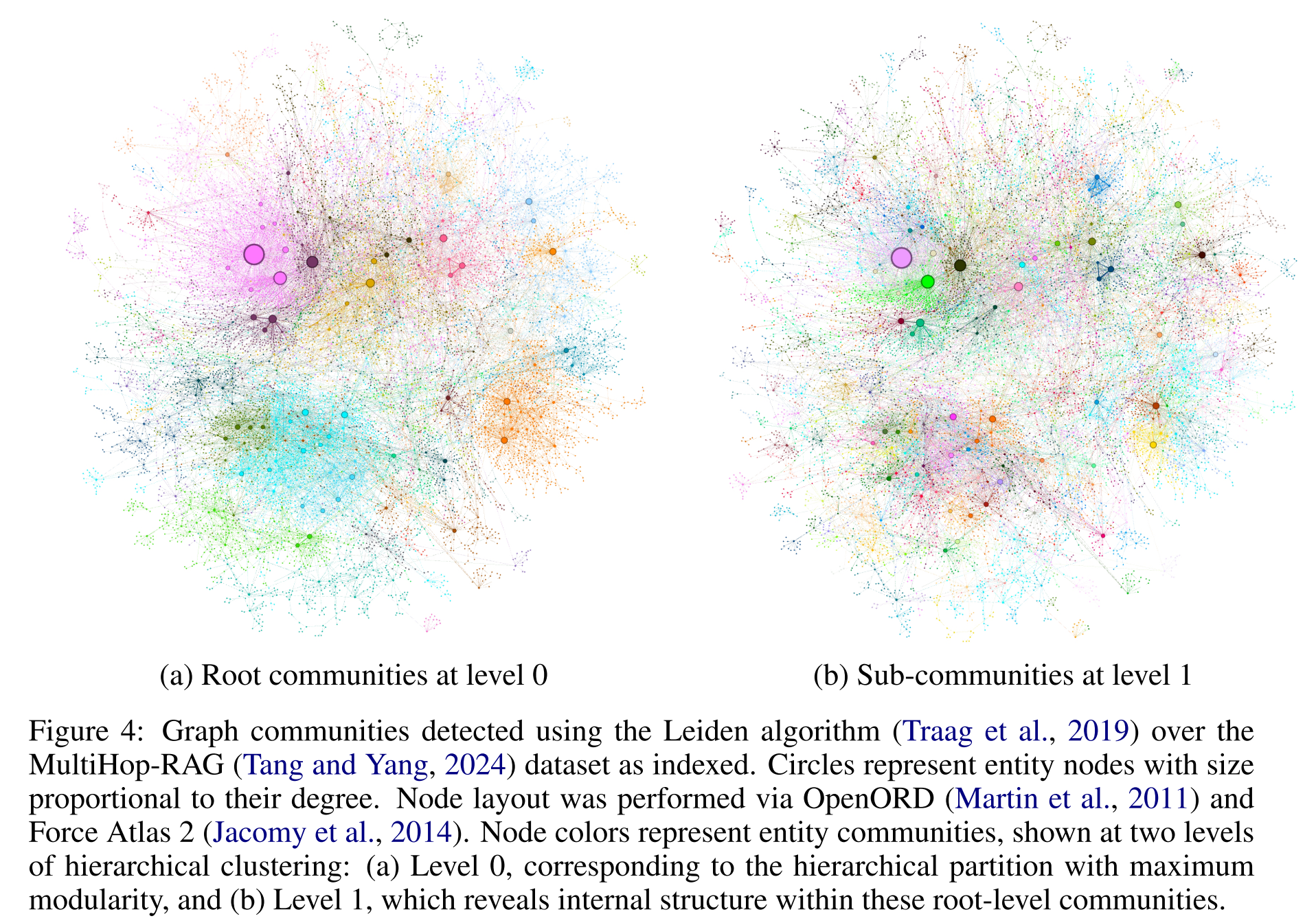
Community detection is used to partition the graph index into groups of elements (nodes, edges, covariates) that the LLM can summarize in parallel at both indexing time and query time.
num of duplicates → edge weights claims → similarity Entities & Relationships → Knowledge Graph
Component Purpose Typical Technique (as described or implied) LLM extraction Identify entities/relations/claims Prompt-based, few-shot examples Entity matching Merge identical names Exact string match (default), fuzzy possible Graph construction Store nodes/edges Simple adjacency list or NetworkX graph Edge weighting Track frequency of relationships Count duplicates Aggregation & summarization Produce node/edge descriptions LLM summarization Community detection Find clusters Leiden algorithm (modularity optimization)
For a given community level, the global answer to any user query is generated as follows:
Prepare community summaries. Community summaries are randomly shuffled and divided into chunks of pre-specified token size. This ensures relevant information is distributed across chunks, rather than concentrated (and potentially lost) in a single context window. Map community answers. Intermediate answers are generated in parallel. The LLM is also asked to generate a score between 0-100 indicating how helpful the generated answer is in answering the target question. Answers with score 0 are filtered out. Reduce to global answer. Intermediate community answers are sorted in descending order of helpfulness score and iteratively added into a new context window until the token limit is reached. This final context is used to generate the global answer returned to the user.