1. Abstract
Background:
- summarization → Traditional RAG works well for specific questions (“When was Company X founded?”), but it struggles with broad, global ones (“What are the main ideas in all these documents?”).
- scalability → (Such questions need summarization of the whole dataset, not just retrieving a few passages — that’s called query-focused summarization (QFS).) Prior QFS methods, meanwhile, do not scale to the quantities of text indexed by typical RAG systems.
- we need to combine scalability and summarization: combines knowledge graph generation and query-focused summarization
Given a question, each community summary is used to generate a partial response, before all partial responses are again summarized in a final response to the user.
1. Introduction
GraphRAG contrasts with vector RAG (text embeddings) in its ability to answer queries that require global sensemaking over the entire data corpus.
2. Background
3. Methods
The high-level data flow of the GraphRAG approach and pipeline:
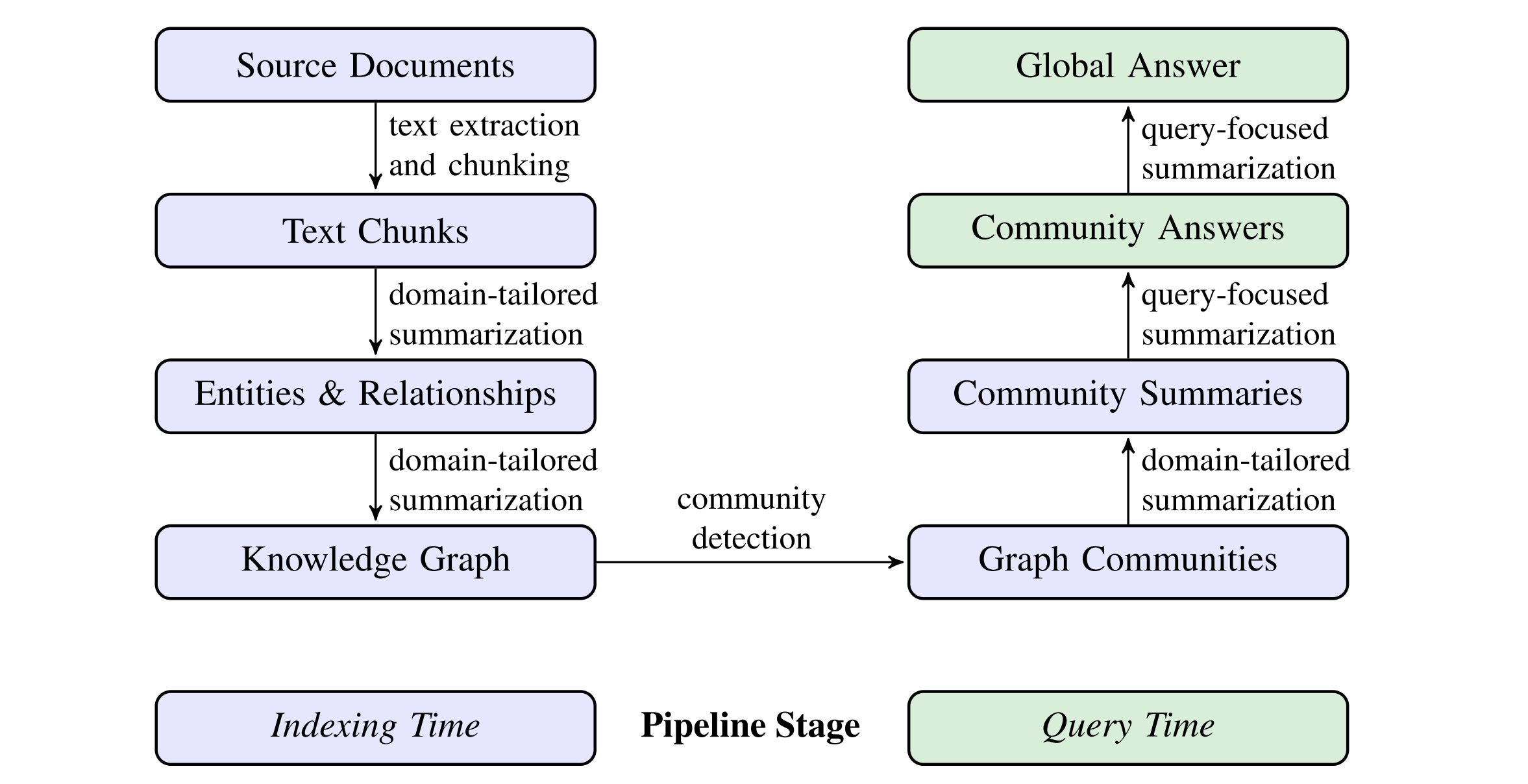
Community detection is used to partition the graph index into groups of elements (nodes, edges, covariates) that the LLM can summarize in parallel at both indexing time and query time.
Entities & Relationships → Knowledge Graph
| Component | Purpose | Typical Technique (as described or implied) |
|---|---|---|
| LLM extraction | Identify entities/relations/claims | Prompt-based, few-shot examples |
| Entity matching | Merge identical names | Exact string match (default), fuzzy possible |
| Graph construction | Store nodes/edges | Simple adjacency list or NetworkX graph |
| Edge weighting | Track frequency of relationships | Count duplicates |
| Aggregation & summarization | Produce node/edge descriptions | LLM summarization |
| Community detection | Find clusters | Leiden algorithm (modularity optimization) |