Introduction
Single image super-resolution (SISR) aims to restore a low-resolution (LR) image into a high-resolution (HR) image with realistic textures. With the growth of deep learning, SISR performance has greatly improved in recent years.
Compared to SISR, reference-based super-resolution (RefSR) makes use of additional high-resolution reference images that share similar textures with the target image. This allows RefSR to generate more detailed and realistic results. Because of these promising results, many researchers have focused on RefSR methods in recent years.
However, all previous RefSR methods are trained with only a single reference image. In practice, there are often multiple reference images available, such as in the CUFED5 dataset, where each LR image has five reference images of varying similarity. Yet, CUFED5’s training set provides only one reference per LR input and contains relatively few and small images. As a result, previous methods cannot effectively use multiple references. To handle multiple references, they often merge them into one large image, which consumes much GPU memory and ignores the relationships between references.
Therefore, a new dataset and method are needed for multi-reference super-resolution. To address this gap, the authors introduce a large-scale multi-reference dataset named LMR, containing 112,142 groups of 300×300 training images, each with five reference images. This dataset is ten times larger than CUFED5 and supports better generalization.
Based on LMR, the authors propose a new method called MRefSR. It introduces two key components:
- Multi-Reference Attention Module (MAM) – fuses features from multiple reference images by treating the LR input as the query and aligned reference features as keys and values.
- Spatial Aware Filtering Module (SAFM) – selects the most relevant fused features to refine the output.
Overall, the work contributes (1) the first large-scale multi-reference RefSR dataset, (2) a new baseline method MRefSR designed for multiple references, and (3) experimental results showing strong improvements over existing methods.
Method
Dataset: Large-scale Multi-reference RefSR dataset LMR
Method: MRefSR
Construction of LMR
The LMR dataset is built based on the MegaDepth dataset, which was originally created for single-view depth prediction. MegaDepth collected over one million Internet photos of landmarks and used COLMAP, a Structure-from-Motion (SfM) and Multi-View Stereo (MVS) system, to reconstruct 3D models and dense depth maps. Each landmark includes many photos taken from different viewpoints, making it suitable for creating image groups with overlapping content, just like reference-based super-resolution (RefSR) requires.
To construct the LMR dataset, the authors first preprocessed MegaDepth to form image pairs with controlled similarity. They used three filtering rules:
- The PSNR between the target and candidate reference images must be lower than 30 dB to remove duplicates.
- The two images must share similar content, ensured by checking the overlap ratio (Rolp) of matched 3D keypoints.
- The size ratio (Rs) of the same object in both images must not be too small, so the reference provides enough detailed texture.
These ratios were computed using the existing D2-Net code. Based on these measures, each image pair was labeled with a similarity level:
- High (H) if Rolp > 30% and Rs > 0.9
- Medium (M) if Rolp > 10% and Rs > 0.66
- Low (L) otherwise
After filtering, the authors obtained large image groups — each with one target image and several reference images. Because training on full images is memory-intensive, they cropped smaller patches. For each group, they first randomly cropped a 300×300 patch from the target image. Then, using 3D keypoints, they located five nearby reference patches from images of different similarity levels (one H, two M, two L).
Finally, this process produced 112,142 training groups, each containing one target patch and five reference patches. This dataset is about ten times larger than CUFED5 and offers much richer multi-reference diversity. For testing, the authors built another set of 142 groups, each with a target image and 2–6 reference images, with resolutions between 800 and 1600 pixels.
Multi-Reference RefSR network
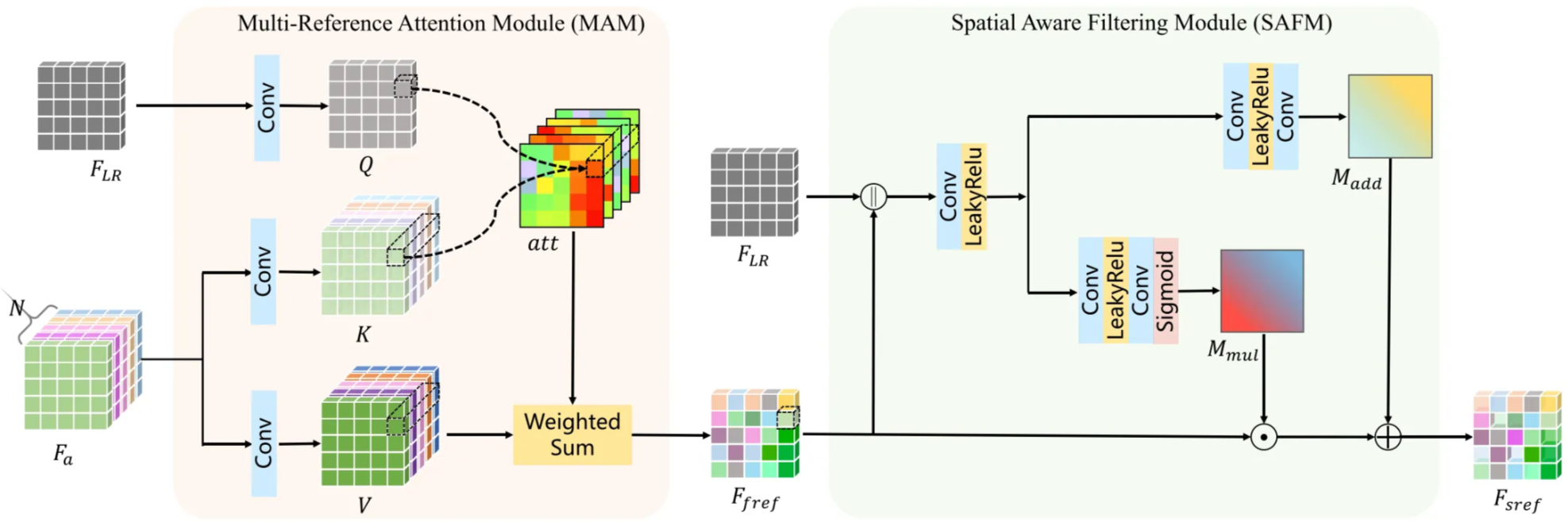
The authors propose a multi-reference RefSR network, called MRefSR, to effectively use multiple reference images. The model is based on C2-Matching, which provides strong performance and open-source accessibility. Like C2-Matching, a Content Extractor (CE) extracts features $F_{LR}$ from the low-resolution $LR$ image, while a VGG extractor extracts multi-scale features $F_{Ref_i}$ from each reference image. The model also uses a pretrained Contrastive Correspondence Network (CCN) to estimate offsets $O_i$, aligning each reference image with the LR input.
After feature extraction and alignment, the network includes two new modules: the Multi-Reference Attention Module (MAM) and the Spatial Aware Filtering Module (SAFM).
- The MAM fuses features from multiple reference images. For each spatial location $(x, y)$, attention maps are generated to measure how similar each aligned reference feature $K_i(x, y)$ is to the LR feature $Q(x, y)$. The attention weights are computed with a softmax function, and all aligned reference features are combined into a fused reference feature $F_{fref}$ using a weighted sum. This allows the model to flexibly handle any number of reference images in both training and testing.
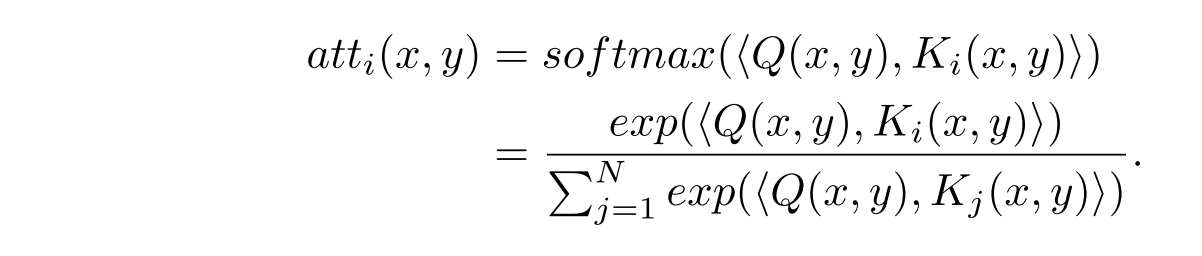
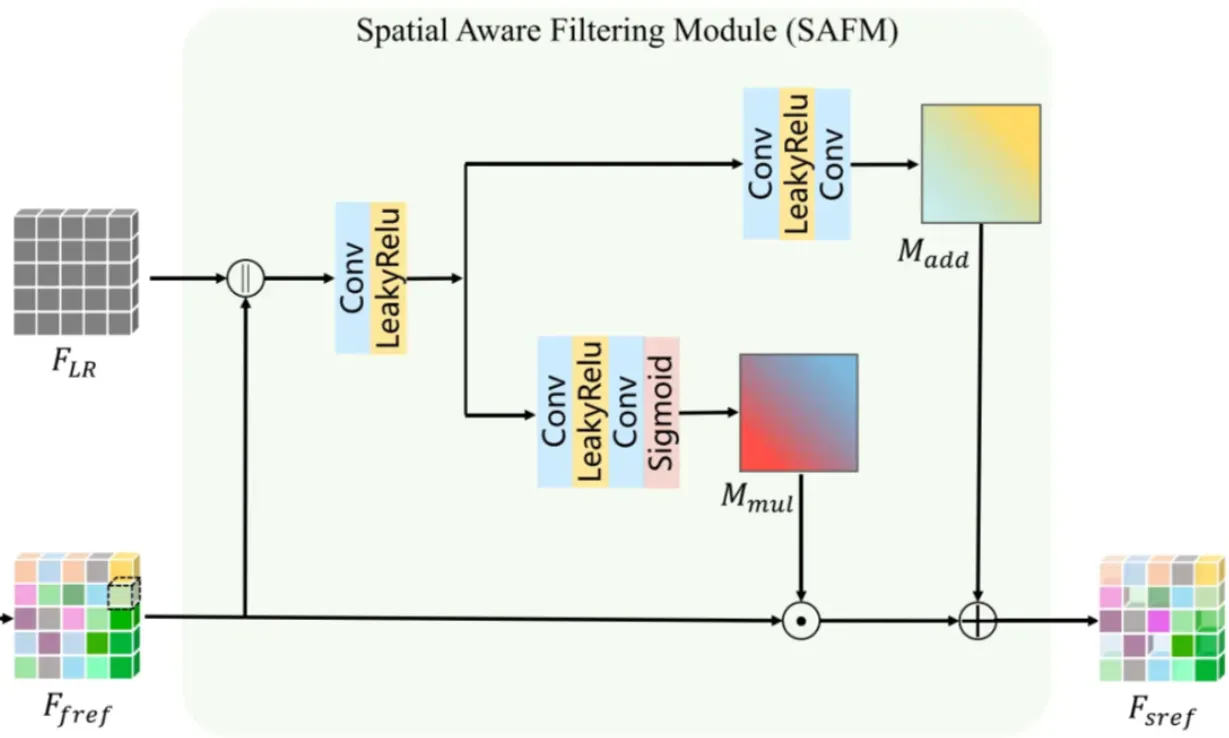
- Next, since not all fused features are reliable, the SAFM selects and refines them. It takes the concatenated features of $F_{LR}$ and $F_{fref}$ as input and generates two masks: a multiplicative mask $M_{mul}$ and an additive mask $M_{add}$. These masks are produced using convolution and Leaky ReLU layers, and $M_{mul}$ is passed through a sigmoid function to keep its values between 0 and 2. The final selected reference feature $F_{sref}$ is obtained by combining the fused feature with these masks.
$$ M_{mul} = \text{sigmoid}(f_1(F_{LR} || F_{fref})) \cdot 2 $$
$$ M_{add} = f_2(F_{LR}||F_{fref}) $$
$$ F_{sref} = F_{fref} \odot M_{mul} + M_{add} $$
$$ X_{SR} = \mathcal{G}(F_{LR}, F_{sref}) $$
where
- $||$ denotes feature concatenation,
- $\odot$ denotes element-wise multiplication,
- $f_1$ and $f_2$ are nonlinear mapping functions (convolutions + LeakyReLU), and
- $\mathcal{G}$ is the restoration module that reconstructs the final super-resolved image.
Finally, a restoration module $G$ takes both the LR features $F_{LR}$ and the selected reference features $F_{sref}$ to reconstruct the high-resolution output image $X_{SR}$.
In summary, MRefSR extends C2-Matching by adding multi-reference attention fusion and spatial-aware filtering, enabling flexible and effective use of multiple reference images for super-resolution.
Conclusion
In this paper, the author proposed a large-scale multi-reference RefSR dataset: LMR. Unlike CUFED5, the only training RefSR dataset available before, LMR has 5 reference images for each LR input image. What’s more, LMR contains 112,142 groups of 300×300 training images, 10 times the number of CUFED5, and the image size is also much larger than CUFED5.
Besides, the author proposed a new multi-reference baseline RefSR method, named MRefSR. A multi- reference attention module (MAM) for feature fusion of an arbitrary number of reference images, and a spatial aware filtering module (SAFM) for the fused feature selection. With LMR enabling multi-reference RefSR training, the method effectively models the relationship among multiple references, thus achieving significant improvements over SOTA approaches on both quantitative and qual- itative evaluations. And the method solves the mismatch problem of previous methods using a single reference image for training but testing with multiple reference images.