blog: https://blog.csdn.net/v_JULY_v/article/details/134923301
S4 video: https://www.youtube.com/watch?v=luCBXCErkCs
Introduction
Foundation models are large pretrained models used for many tasks like text, image, and audio. Most of them are built on the Transformer, which uses attention to connect information between tokens. However, attention is slow and limited to a fixed window, and its cost grows very fast with sequence length. Many improved versions exist, but none perform as well as Transformers at scale.
Structured State Space Models (SSMs) are efficient sequence models inspired by RNNs and control theory. They can model long sequences with linear time complexity and work well on continuous data like audio or vision. But they still perform poorly on discrete data such as text because they cannot focus on relevant information.
The paper proposes Selective SSMs that let model parameters depend on the input. This helps the model decide what to keep or forget based on the content, similar to attention. The authors also design a new hardware-efficient algorithm to make it run fast and truly linear in sequence length.
The resulting Mamba architecture combines these selective SSMs into a simple, recurrent model. Mamba trains and runs much faster than Transformers, handles very long contexts, and needs less memory.
Experiments show Mamba performs as well as or better than Transformers across language, audio, and genomics tasks. It reaches Transformer-level accuracy with only half the size and runs up to 5× faster. Mamba proves that efficient, attention-free models can match Transformer quality while scaling to very long sequences.
Method
1. Problems
- Transformers are powerful but slow and memory-heavy (quadratic cost).
- Existing efficient models (like SSMs, RNNs) are not content-aware — can’t decide what to remember or ignore.
- Recurrent models are often hardware-inefficient on GPUs.
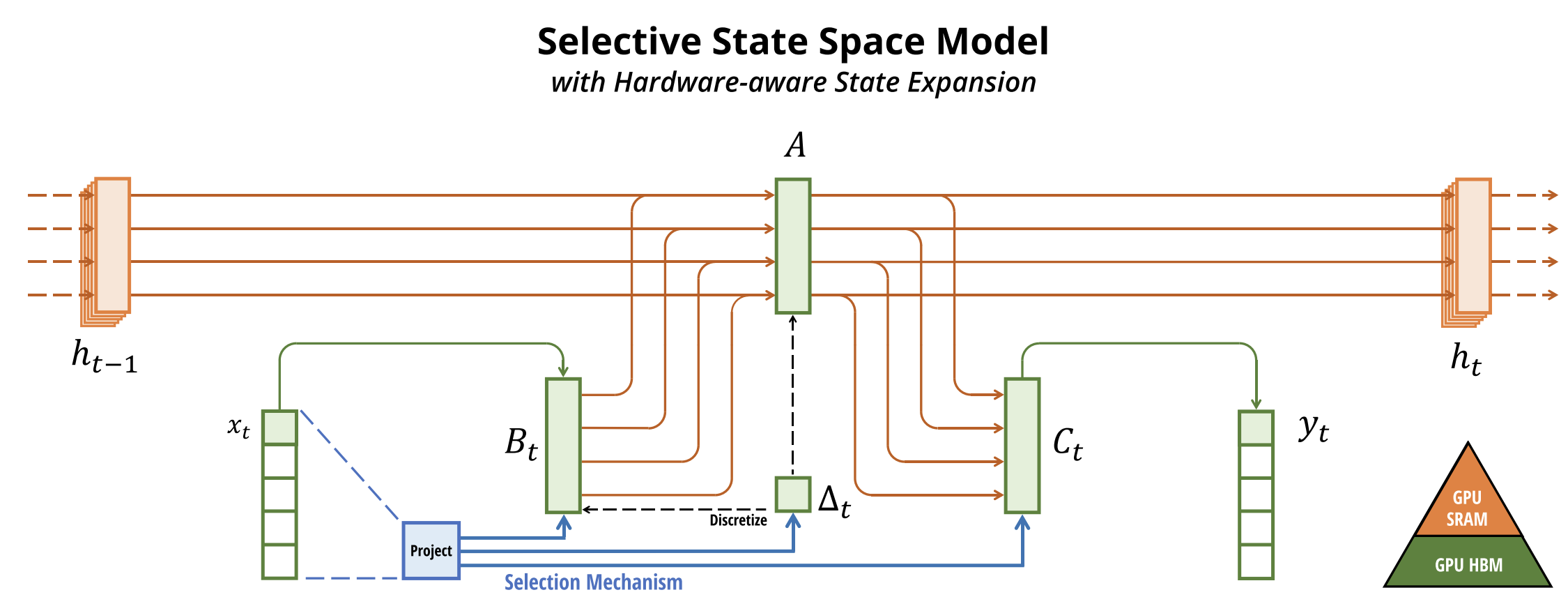
2. Architecture
- Mamba uses a new Selective State Space Model (SSM).
- Adds a selection mechanism so parameters depend on the input (content-aware).
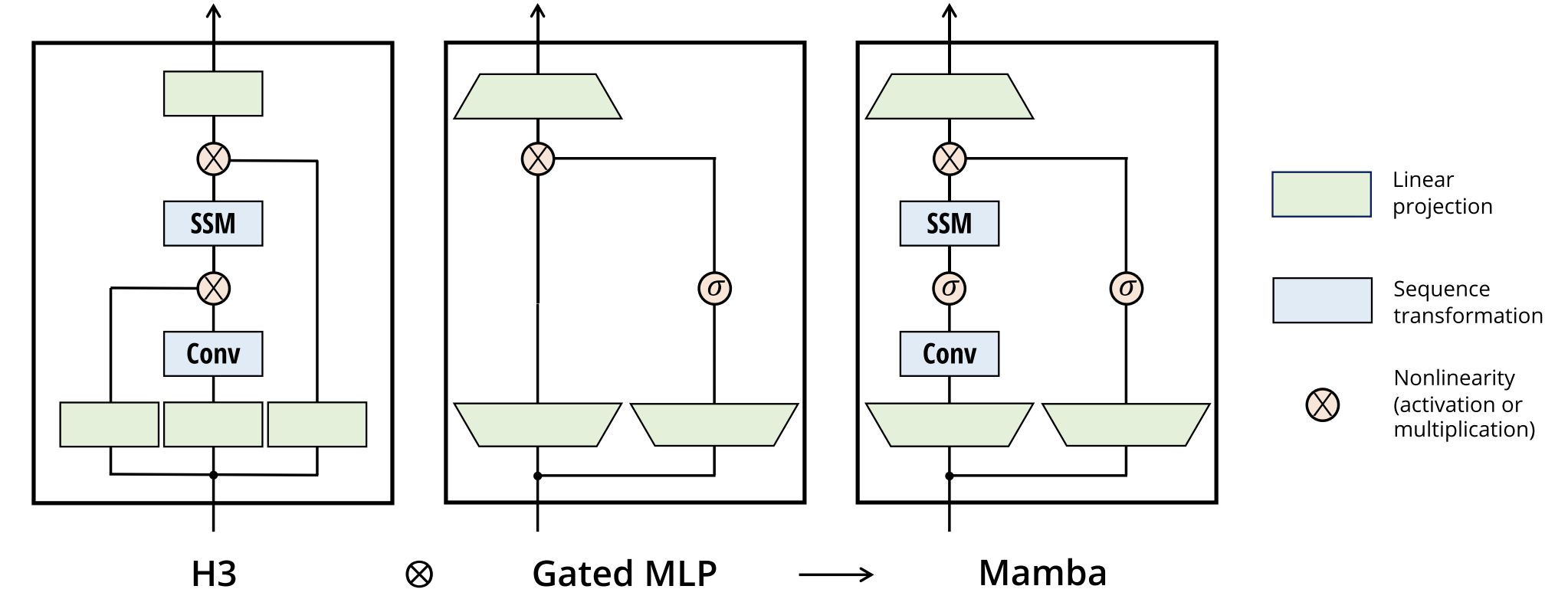
- Each layer combines one Conv (local info) and one SSM (long memory) into a simple, unified block.
3. Noval
- Selective mechanism:
- Traditional SSMs use fixed matrices A, B, C
- Mamba updates them input-dependent: A, B, C, Δ → adaptive reasoning.
- Hardware-aware selective scan:
- optimized GPU recurrence using fast SRAM.
- Practical simplified architecture:
- Removes heavy math from S4 (HiPPO kernel, complex eigenvalues)
- Uses simple parameterization + gating
- Makes SSMs trainable and stable in large models
Result:
Mamba keeps linear-time efficiency, adds attention-like adaptability, and achieves Transformer-level or better performance up to 5× faster.