Introduction
AlphaGo
AlphaGo combines CNN with MCTS to play Go at a superhuman level.
It first trains two types of networks (policy network & value network & rollout policy), using the current game board combined with several handcrafted Go features as input:
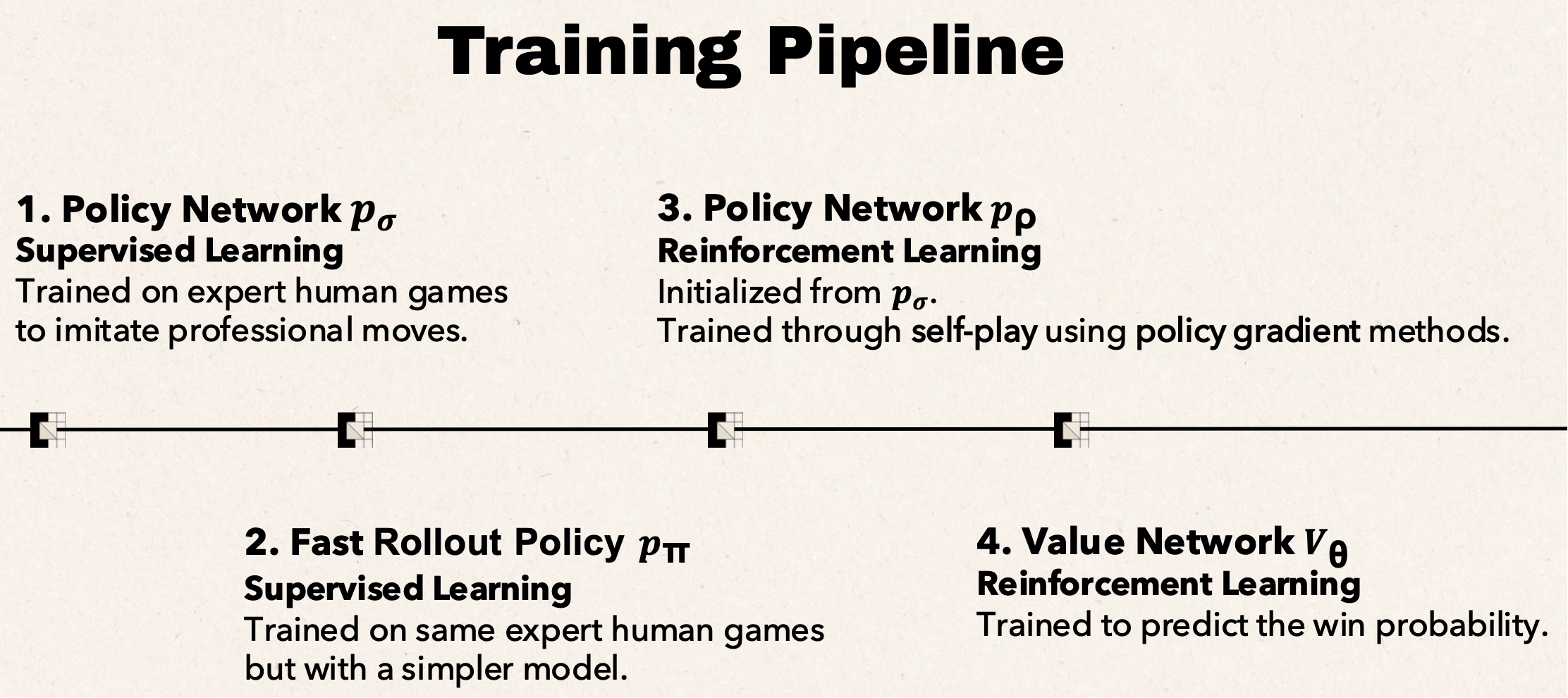
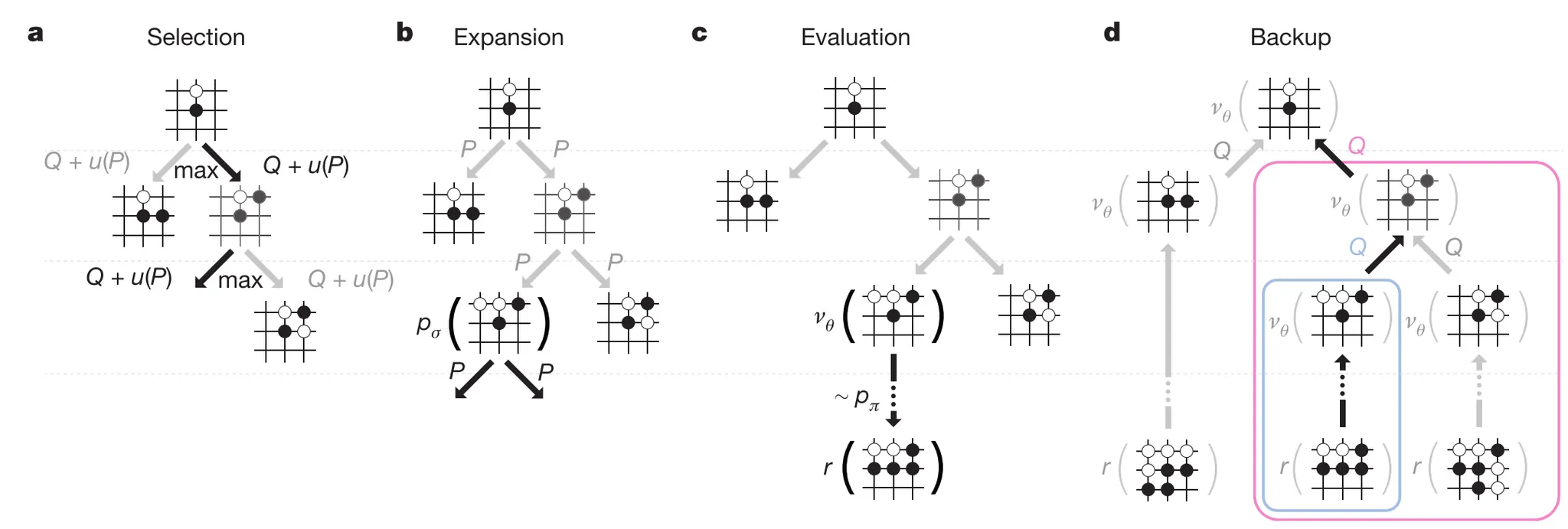
Then integrates the networks into MCTS to enhance the basic tree search.
AlphaGo Zero
AlphaGo Zero combines a deep residual network ResNet with MCTS. Unlike AlphaGo, where MCTS is separate from training, AlphaGo Zero integrates MCTS directly inside the training loop.
It trains a single unified network (two heads, produce policy and value outputs) directly from raw board positions, without using any human games or handcrafted Go features.
Train the model to minimize the gap between p and π | v and z.
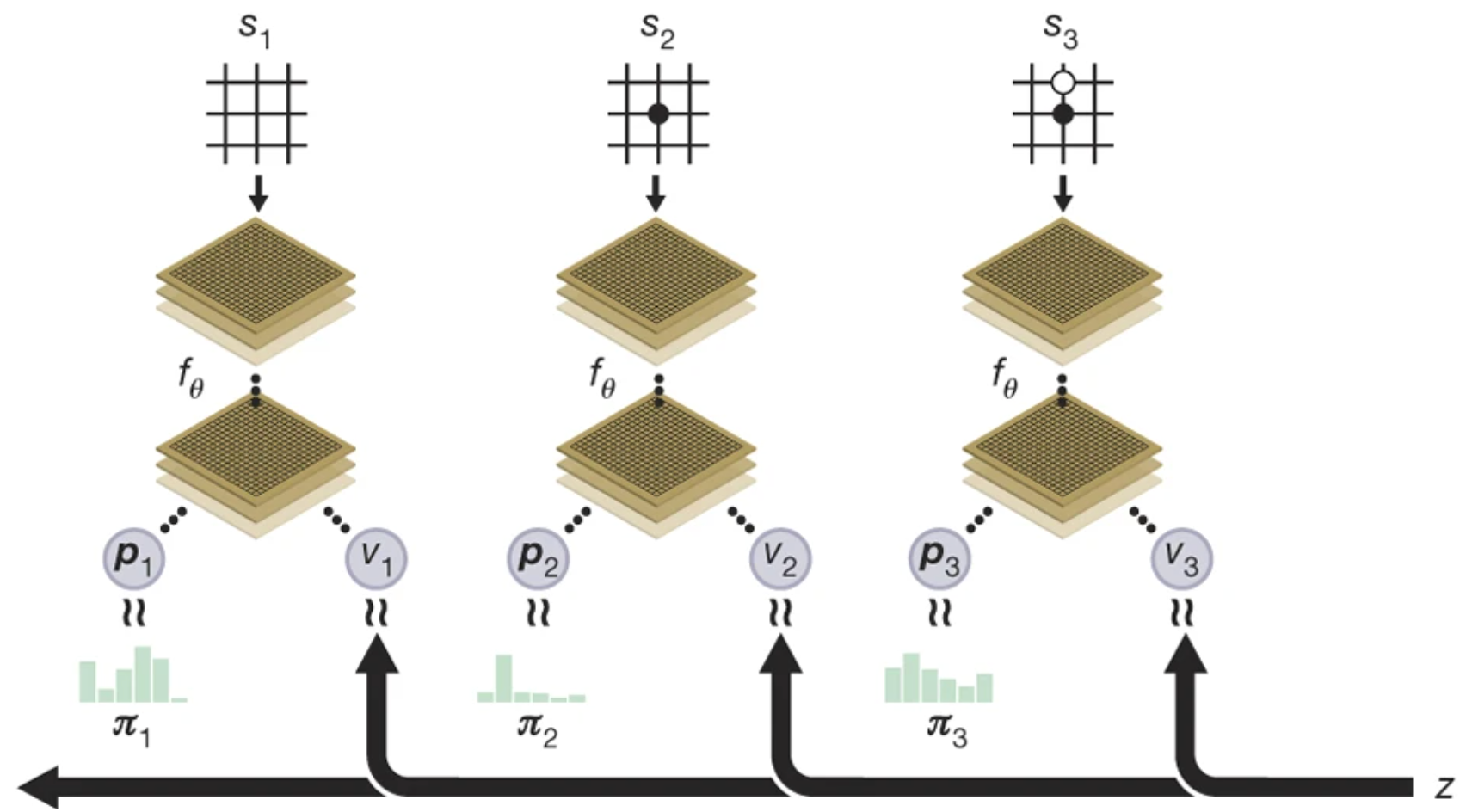
How to choose the next move? → Policy as prior probability in MCTS. The actual move is always selected based on the MCTS-improved policy π, produced after many MCTS simulations.
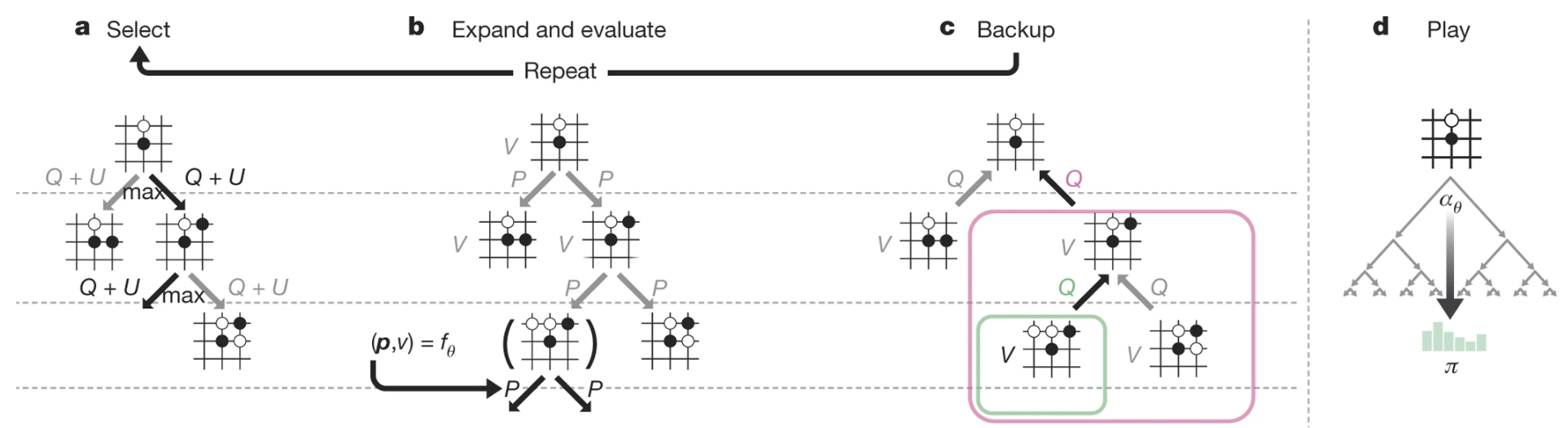
Method
AlphaZero generalizes AlphaGo Zero to Go, Chess, and Shogi using one unified algorithm.
- It removes all handcrafted knowledge and relies only on the basic game rules.
- A single neural network $f_\theta(s)$ outputs both the policy p and value v from the raw board.
Training
MCTS uses this network to produce an improved policy $\pi$, which selects moves and supervises training. Self-play generates $(s, \pi, z)$ data, and training minimizes value error $(z - v)^2$ and policy cross-entropy $-\pi^\top \log p$.
The same network is updated continuously, with no best-player selection stage. Hyperparameters are reused across games, and the board is encoded only by simple rule-based planes with no extra features.
Novelty
Compared with AlphaGo Zero:
- AlphaZero works for multiple games, not only Go.
- Predicts expected outcome (handles draws), not just win/loss.
- Removes all symmetry augmentation and board transformations.
- Uses one continuously updated network, no best-player selection.
- Reuses one set of hyperparameters across all games.