ALTA is a new programming language and a compiler that can map ALTA programs to Transformer weights.
It can help clearly analyze what algorithms Transformers can represent, why sometimes fail to learn them, and how to design models that generalize compositionally.
1. Proposed Framework
1.1. Overview

An ALTA Program Example - parity
A Transformer can implement this parity algorithm because:
Residual stream = variables stored inside the hidden vector
(“store parity and done as part of the hidden state”)
Attention = lookup from other tokens
(“give me the value from the previous token”)
FFN/MLP = local computation
(“compute new parity from old parity”)
The ALTA framework includes:
- an interpreter
- symbolically executes a program,
- a compiler
- compiles programs to Transformer weights.
1.2. Variables
There are three kinds of variables ALTA supports:
- Categorical variables
- Value is from a small finite set (e.g.,
{0,1},{A,B,C}) - Represented as one-hot vectors inside the Transformer
- Value is from a small finite set (e.g.,
- Numerical variables
- Real-number values
- Represented as a single neuron (one scalar dimension)
- Set variables
- Values are sets of integers (e.g.,
{1, 4, 7}) - Represented as multi-hot vectors
- Values are sets of integers (e.g.,
- Attention-head outputs as variables
- Some variables come from attention heads
- These can take a null / undefined value (e.g., when a head attends to no token)

One residual block
The residual stream is the single vector per token that all sublayers read and write.
1.3. Execution
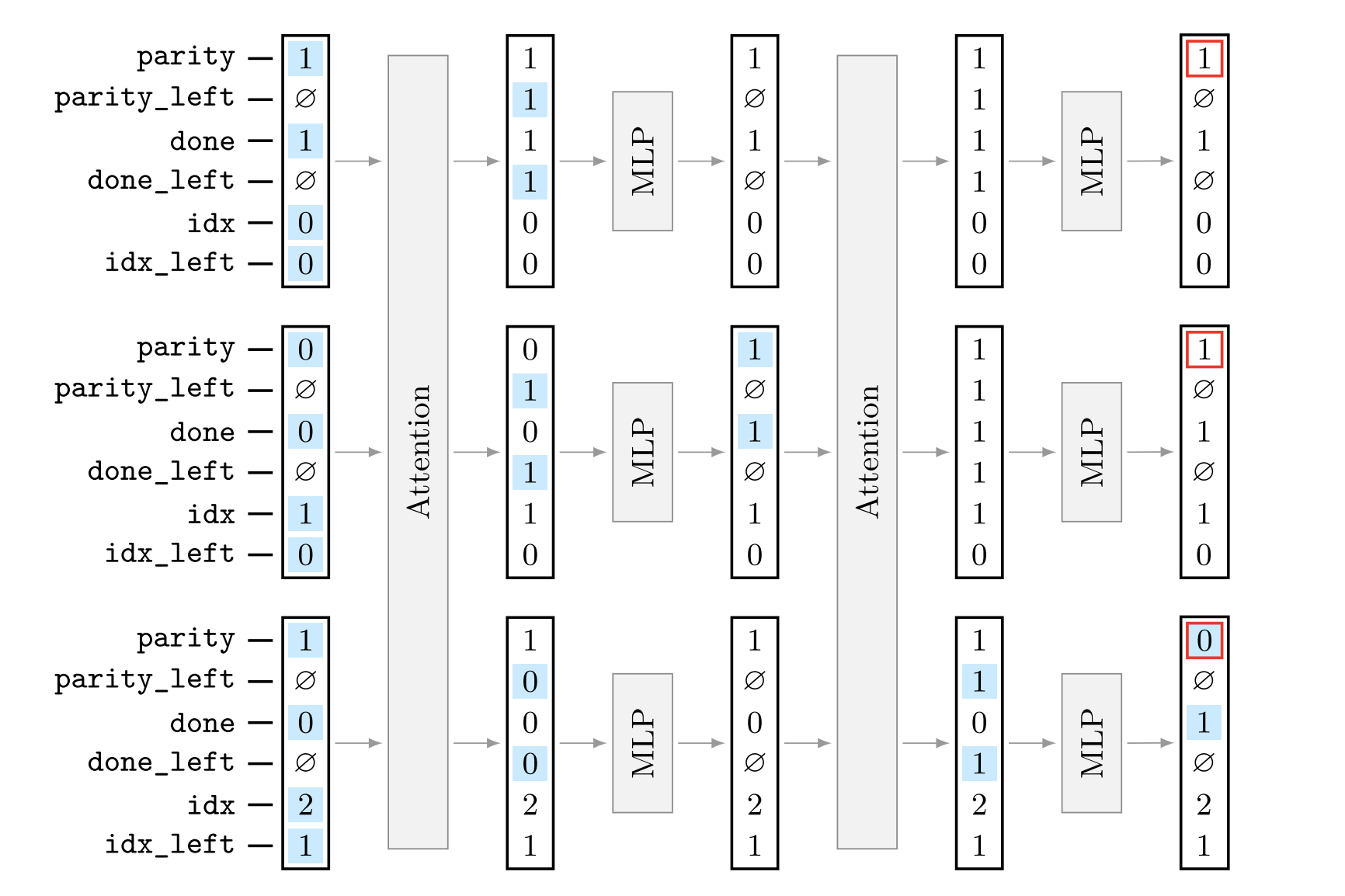
ALTA represents each token’s state with symbolic variables, which correspond to segments of the Transformer’s residual vector.
Initialization: Input and position-dependent variables are encoded directly into the initial residual stream using embeddings.

Per-layer execution
Self-attention:
select(query, key)builds a binary attention pattern based on variable equality.aggregatecollects the correspondingvaluevariables.- This produces inter-token variables like
parity_left.
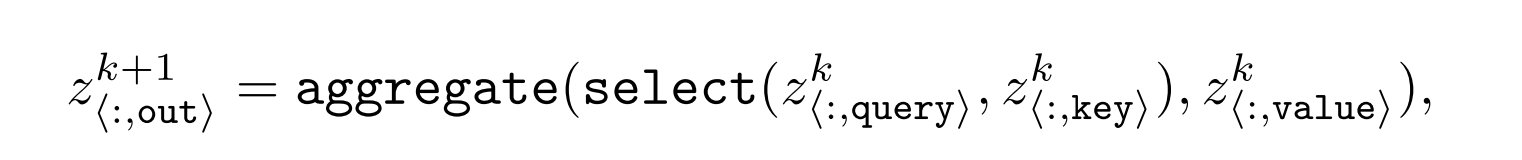
MLP:
- Defined by symbolic transition rules.
- Compiler turns these into a fixed 4-layer ReLU network that updates variables (e.g.,
parity,done).
Residual updates: Attention and MLP outputs are added to the residual stream, as in standard Transformers.
Halting & output: Execution stops when a halting condition is met; the specified output variable is read from the final residual stream.
2. Expressibility and Learnability
2.1. Expressibility
ALTA shows constructively that Transformers can exactly implement algorithms like parity, addition, and SCAN.
2.2. Learnability
Even if an algorithm is expressible by a Transformer, training on input–output pairs may fail to learn it.
ALTA provides two tools to analyze and improve learnability:
- Trace supervision: Use ALTA’s intermediate states as supervision to help training follow the intended algorithm.
- Minimality analysis: A program must be minimal on the training set for the compiled Transformer weights to be a stable solution; non-minimal programs lead to unstable or incorrect learning.
3. ALTA Summary
Six sentences to summarize ALTA:
- ALTA is a formal programming language that describes the computation inside a transformer in a human-interpretable way. It converts opaque neural operations into clear algorithmic steps.
- ALTA includes a compiler that translates an ALTA program into actual transformer weights (embeddings, attention, FFN).
- ALTA programs use explicit symbolic variables (e.g., idx, parity, done, parity_left) to track interpretable token-level states throughout the computation.
- Attention in ALTA implements inter-token communication, enabling a token to read variables from other positions (e.g., computing left-side context like parity_left).
- FFNs implement intra-token updates, modifying the variables of each token based only on its own state (e.g., updating parity or flags).
- Because attention moves information only one step per layer, n tokens often require O(n)(n-1) layers for full information propagation.