⁉️ Why Bayesian Optimization Finally Beat Random Search
A Beginner-Friendly Review of the NeurIPS 2020 Black-Box Optimization Challenge.
Hyperparameter tuning sounds boring — but it quietly determines the final performance of almost every machine learning model.
Yet most researchers still rely on manual tuning, grid search, or random search.
In 2020, a large international competition decided to answer a simple but important question:
Is Bayesian Optimization really better than Random Search for hyperparameter tuning?
The results?
A decisive yes — and even more interesting insights about how top teams achieved massive improvements.
This article gives you a simple, intuitive overview of the entire paper and competition.
🌟 1. Background: Why This Competition Matters
Hyperparameter tuning is a black-box optimization problem:
You adjust parameters → train a model → observe the score → repeat.
You don’t know the shape of the loss surface or its derivatives.
The ML community has long believed Bayesian Optimization (BO) should outperform random search — but large-scale, ML-focused benchmarks were missing.
The NeurIPS 2020 challenge filled this gap:
- 65 teams participated
- Hyperparameter tuning tasks came from real scikit-learn models and real datasets
- All evaluations were done in a secure Docker environment
- Final scores were based on hidden test problems to prevent overfitting
The goal was simple:
Find the most effective black-box optimizer for ML hyperparameters.
🔧 2. How the Competition Worked
The organizers built a “dataset of optimization tasks”:
- Different ML models
- Different datasets
- Different evaluation metrics
This created dozens of unique problems such as:
- Tune GBDT on MNIST (accuracy)
- Tune logistic regression (log loss)
- Tune MLP on Boston housing (RMSE)
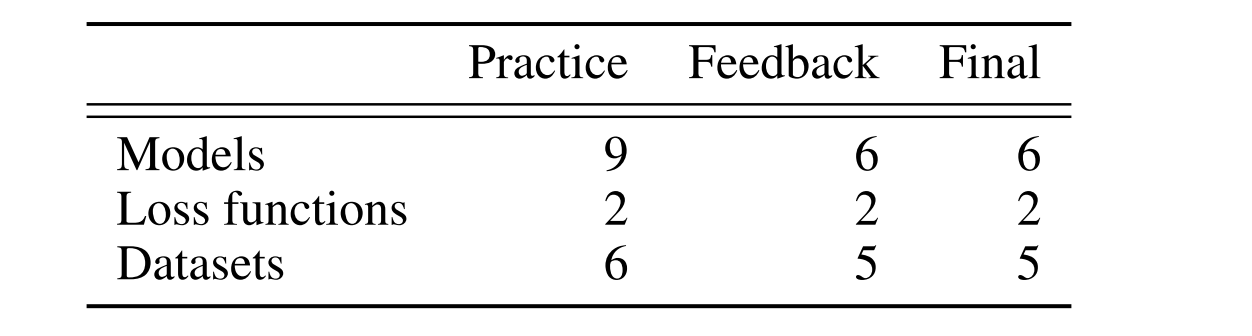
A summary of the different model, loss, and data set combinations that made up the different phases.
Participants submitted an optimizer, not hyperparameters.
Their optimizer could:
- Suggest() k hyperparameter candidates
- Observe() the returned scores from the benchmark
Each submission had:
- 16 rounds
- Batch size = 8 evaluations per round
- Total = 128 evaluations per problem
- 640 seconds runtime limit per problem
All practice problems were public, but feedback and final problems were completely hidden.
This design ensured:
- Fairness
- No leaking of datasets
- No manual tuning on test problems
📊 3. How Scores Were Calculated (Super Simple Version)
Scoring used the Bayesmark system:
- Random Search average → normalized score = 1
- Best possible performance → normalized score = 0
Then scores were transformed to a final leaderboard value:
🥇 Score = 100 × (1 – normalized_mean_performance)
So:
- 100 = always finds best hyperparameters
- 0 = no better than random search
This created a clean, unitless, intuitive 0–100 scale.
🏆 4. What Actually Worked? Key Insights from the Top Teams
Insight 1: Bayesian Optimization dominates
Out of 65 teams:
- 61 beat random search
- Almost all top submissions used surrogate models + acquisition functions
- The best solutions achieved 100× sample efficiency vs random search
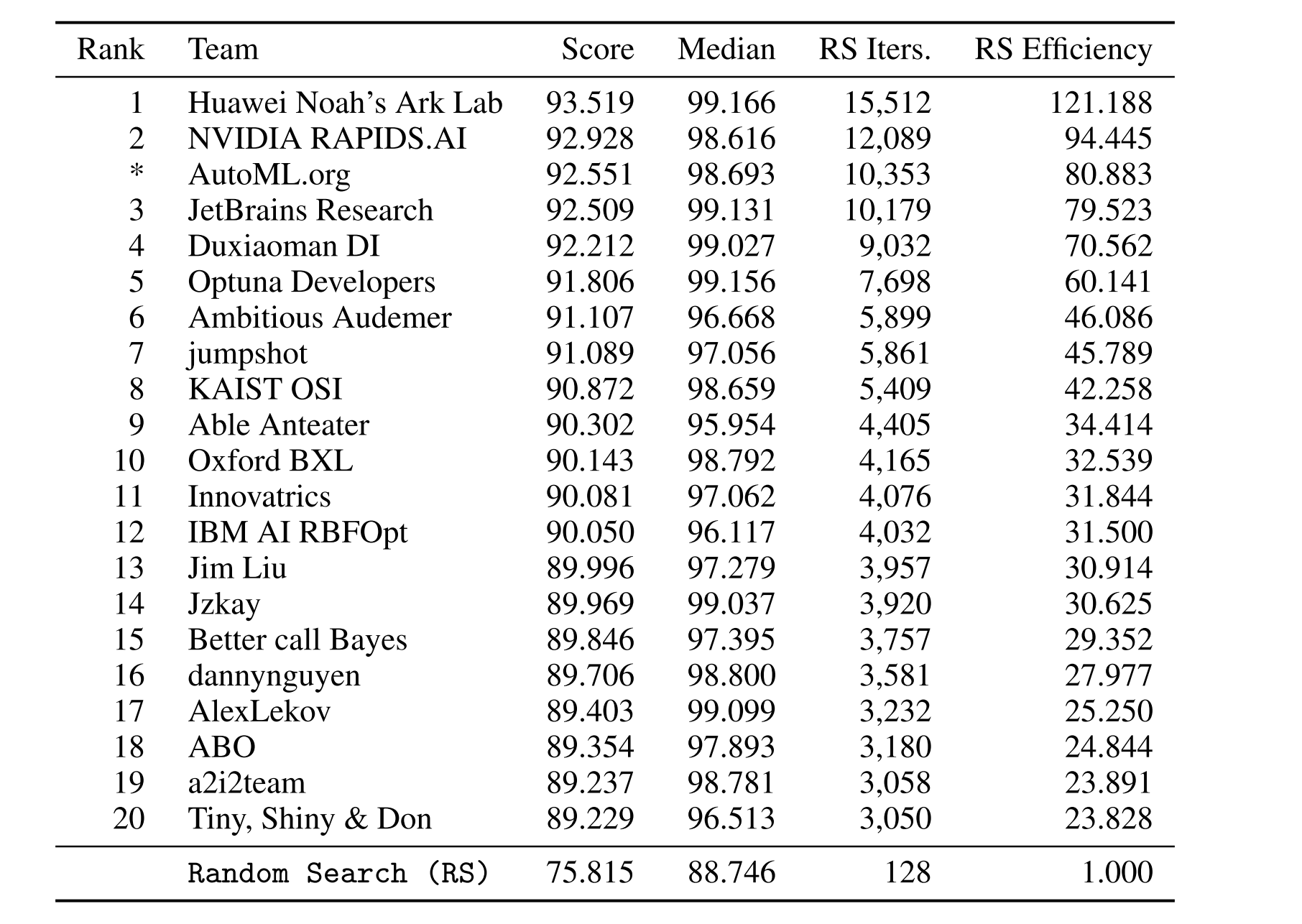
Insight 2: Trust-region BO (TuRBO) is incredibly strong
TuRBO (a local BO method) was the strongest baseline and appeared in 6 of the top 10 solutions.
This suggests:
In hyperparameter tuning, the landscape is often locally structured, so local models work well.
Insight 3: Ensembles win — even simple ones
Every top-10 team used some form of ensemble.
This was the biggest surprise.
Examples:
- NVIDIA combined TuRBO + Scikit-Optimize (50).
- Duxiaoman combined TuRBO + pySOT.
- AutoML.org used a more complex combination with differential evolution in later rounds.
These ensembles consistently outperformed their components, especially avoiding failure cases where one method gets stuck.
Insight 4: Handling categorical/discrete integer variables matters
Most BO literature focuses on continuous parameters, but ML models often include:
- number of layers
- max_depth
- activation choices
- categorical losses
Some teams modified TuRBO or used bandit-style strategies to better treat these.
This gave additional performance boosts.
Insight 5: Meta-learning & Warm Starting can skyrocket performance
During the feedback phase, teams noticed patterns:
- “Similar models like similar hyperparameters.”
Some teams used meta-learning:
- Use good hyperparameters from similar past problems
- Warm-start the optimizer near plausible good regions
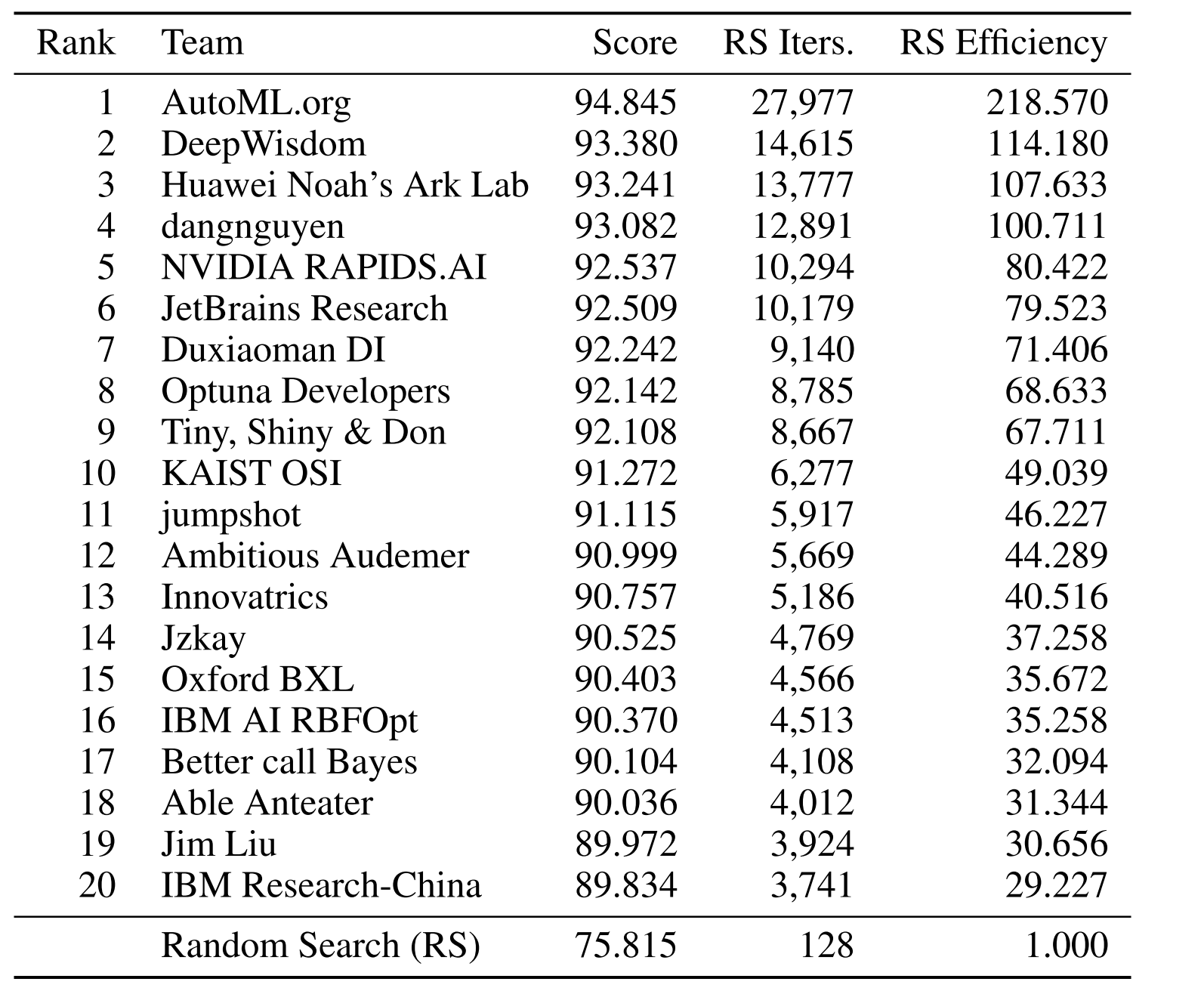
When parameter names were revealed in a controlled “warm start experiment,”
AutoML.org jumped to 1st place with huge gains.
🎯 5. Main Takeaways for Practitioners
1. Always prefer BO over random search
The competition provided the clearest proof so far.
Even simple BO implementations gave orders of magnitude better results.
2. If you don’t know what to use → start with TuRBO
It performed well out-of-the-box across all tasks.
3. Ensembling is a cheat code
Even a basic 50/50 ensemble of two optimizers can dramatically improve stability and performance.
4. Don’t ignore categorical parameters
A small adjustment to treat them properly can make your optimizer more robust.
5. Warm-start when you can
If you repeatedly solve similar ML tasks, reuse previous experience.
🔮 6. Future Directions
The authors highlight several exciting extensions:
- multi-fidelity optimization (early stopping, partial data)
- asynchronous parallel BO
- adding constraints or multi-objective settings
- giving partial model information to optimize smarter
🧾 7. Conclusion
The NeurIPS 2020 Black-Box Optimization Challenge delivered a clear message:
Bayesian Optimization is not only better than random search — it’s much better.
With simple ensembles and trust-region methods, teams achieved more than 100× speedups in sample efficiency.
This competition set a new benchmark and provided practical insights that anyone doing ML hyperparameter tuning can benefit from.