Problem
Self-attention in Transformers is built on query–key dot products, which are widely believed to be essential for modeling token interactions and long-range dependencies. However, it is unclear whether this content-based, pairwise similarity computation is truly necessary for good performance.
The paper questions three common assumptions:
- That attention weights must be computed from token–token interactions (Q·K)
- That attention must be instance-specific rather than globally learned
- That dot-product attention is the key reason for Transformer success
In short, the problem is to understand how important dot-product self-attention really is, and whether simpler or alternative mechanisms can replace it without hurting performance .
Method
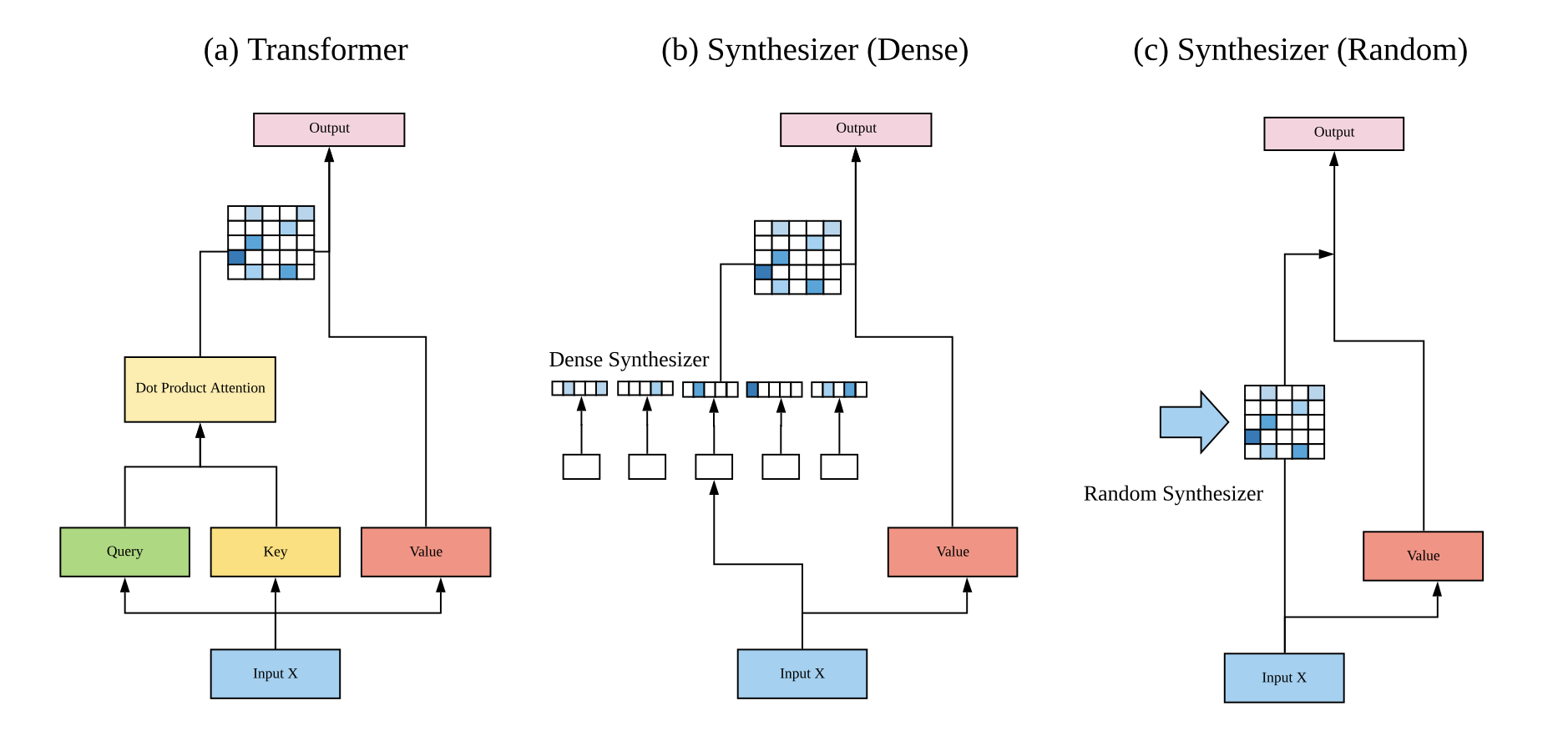
The paper proposes Synthetic Attention, which removes query–key dot products entirely and instead directly learns (or generates) the attention/alignment matrix.
Core idea:
The proposed SYNTHESIZER replaces standard self-attention with:
Dense Synthesizer:
Each token independently predicts its attention weights using an MLP (no token–token interaction).
Random Synthesizer:
Attention weights are global, randomly initialized matrices (trainable or fixed), shared across all inputs.
Factorized Synthesizers:
Low-rank versions to reduce parameters and improve efficiency.
Mixture Models:
Combine synthetic attention with dot-product attention, showing they are complementary.
The model keeps the rest of the Transformer unchanged (values, feed-forward layers, multi-head structure) and is evaluated across machine translation, language modeling, text generation, and GLUE/SuperGLUE benchmarks.
Results show that synthetic attention alone is often competitive, and combining it with dot-product attention can outperform standard Transformers .